ChatGPT maker OpenAI has unveiled 'Sora', a new tool that can create realistic-looking videos based on text prompts from users.
"Introducing Sora, our text-to-video model. Sora can generate videos up to a minute long while maintaining visual quality and adherence to the user's prompt," the company said in a statement.
OpenAI CEO Sam Altman in a post on X said the company was "offering access to a limited number of creators". He also appreciated the efforts of the Sora team.
here is sora, our video generation model:https://t.co/CDr4DdCrh1
February 15, 2024
today we are starting red-teaming and offering access to a limited number of creators.@_tim_brooks @billpeeb @model_mechanic are really incredible; amazing work by them and the team.
remarkable moment.https://t.co/WJQCMEH9QG pic.twitter.com/Qa51e18Vph
February 15, 2024"Today, Sora is becoming available to red teamers to assess critical areas for harms or risks. We are also granting access to a number of visual artists, designers, and filmmakers to gain feedback on how to advance the model to be most helpful for creative professionals," OpenAI said.
"We're sharing our research progress early to start working with and getting feedback from people outside of OpenAI and to give the public a sense of what AI capabilities are on the horizon," the company said.
Sora can generate complex scenes with multiple characters, specific types of motion, and accurate details of the subject and background. The model understands not only what the user has asked for in the prompt, but also how those things exist in the physical world.
The model has a deep understanding of language, enabling it to accurately interpret prompts and generate compelling characters that express vibrant emotions.
Sora can also create multiple shots within a single generated video that accurately persist characters and visual style.
The company said that the current model has weaknesses.
"It may struggle with accurately simulating the physics of a complex scene, and may not understand specific instances of cause and effect. For example, a person might take a bite out of a cookie, but afterward, the cookie may not have a bite mark," the statement said.
Sora may also confuse spatial details of a prompt, for example, mixing up left and right, and may struggle with precise descriptions of events that take place over time, like following a specific camera trajectory.
Regarding the safety element, OpenAI said that it will be taking several important safety steps ahead of making Sora available in their products.
'We are working with red teamers — domain experts in areas like misinformation, hateful content, and bias — who will be adversarially testing the model," the company said.
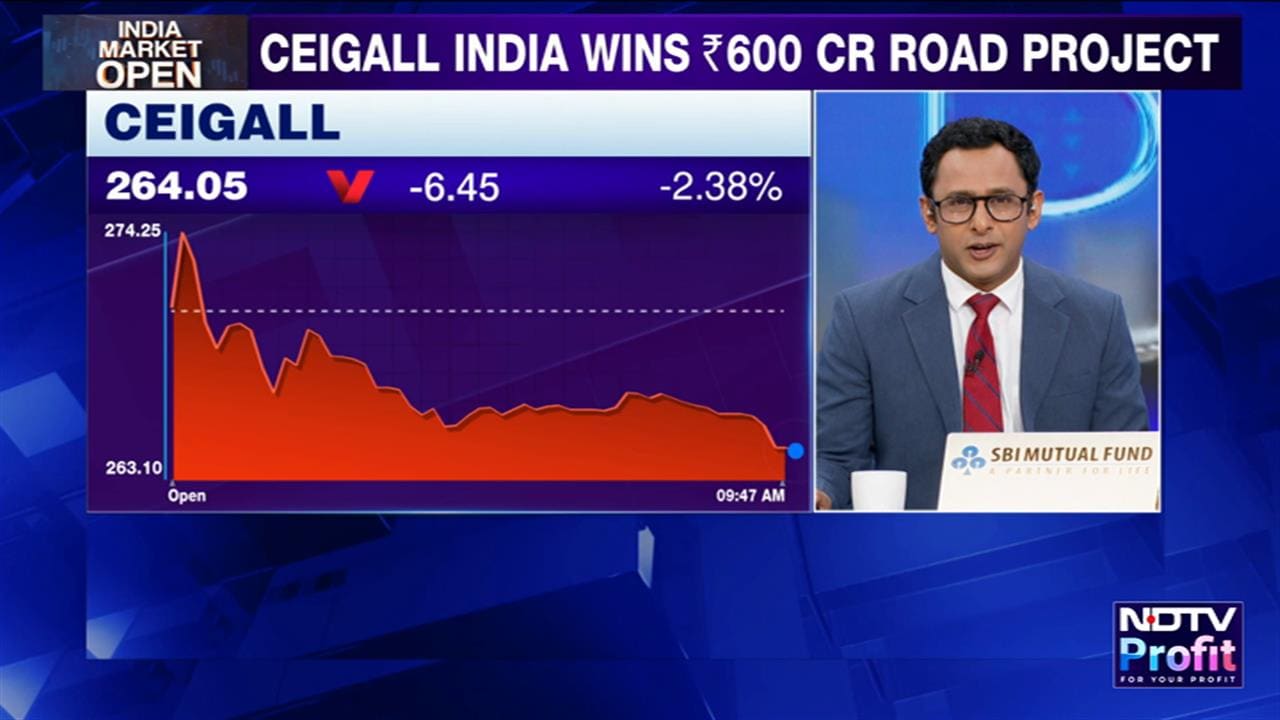
Essential Business Intelligence, Continuous LIVE TV, Sharp Market Insights, Practical Personal Finance Advice and Latest Stories — On NDTV Profit.